

Il Garante per la privacy ha mosso alcuni rilievi a ChatGPT. OpenAI ha di dichiarato che nei prossimi giorni lavorerà per trovare una soluzione, nel frattempo ha sospeso il servizio in Italia. Peccato, stavamo iniziando a divertirci in redazione. In questo articolo descriviamo alcuni esperimenti di utilizzo in situazioni reali di questa nuova e potente tecnologia (Immagine di Stable Diffusion. Prompt: Artificial intelligence in office with colleagues. Neon light, beautiful and colorful).
Vogliamo raccontarvi come stavamo provando a trovare compiti da assegnare a ChatGPT per renderne sistematico l’utilizzo nella redazione di Scienza in rete prima che venisse tolto dalla disponibilità degli utenti italiani.
Come noto il Garante per la protezione dei dati personali venerdì 31 marzo (2023) ha sollevato alcune questioni che hanno avuto come conseguenza il blocco di ChatGPT. Ecco le tre considerazioni consegnate dal Garante a OpenAI, la società che ha creato ChatGPT: anzitutto OpenAI non protegge adeguatamente la privacy degli utenti; in secondo luogo non applica un filtro per impedire l’accesso ai minori i quali, da ultimo, sono maggiormente esposti ai danni causati dalle risposte “inidonee” della AI. Il garante ha esortato OpenAI a dare una risposta in merito entro 20 giorni, pena la chiusura del servizio e una multa consistente (4% del fatturato della società). OpenAI a scanso di equivoci ha deciso di rendere la propria AI irraggiungibile dall’Italia e con una mail ha spiegato agli utenti plus (come la redazione di Scienza in rete) le ragioni dell’interruzione del servizio: «Ci impegniamo a proteggere la privacy delle persone e crediamo di offrire ChatGPT in conformità con GDPR e altre leggi sulla privacy. Ci impegneremo con il Garante con l’obiettivo di ripristinare il tuo accesso nel più breve tempo possibile».
Probabilmente proprio negli stessi giorni in cui il Garante stava riflettendo sui rilievi da consegnare a OpenAI, all’interno della redazione stavamo discutendo di una criticità che sembrava più urgente non solo a noi ma a tutta la comunità delle persone coinvolte direttamente nella ricerca e sviluppo della AI: il pericolo che questa tecnologia possa diventare appannaggio di poche ed enormi multinazionali, sempre più chiusa e orientata solo a fini commerciali (come sembra proprio il caso di OpenAI). Per esempio il 29 marzo, LAION, una organizzazione no profit che ha creato il dataset per il training di Stable Diffusion (una AI open source che genera immagini), ha pubblicato una petizione con cui si chiede che venga creata una organizzazione che si occupi di rendere trasparente e aperto lo sviluppo delle AI.
Intanto stavamo iniziando a prendere confidenza con questa (e le altre) AI per capire quali fossero i “promt” più efficaci: le varie AI hanno caratteristiche diverse e i programmatori rilasciano documenti in cui descrivono quali siano i comandi da usare per ottenere risultati desiderati. Qui per esempio le guide ai prompt di Midjourney di Stable Diffusion, di ChatGPT.
Le AI sono strumenti che possono fare cose utili in generale per gli umani, ma decisamente utili anche in una redazione. Sembra di avere accesso immediato e illimitato a una risorsa con enormi potenzialità. In realtà da subito ci siamo posti la questione della sostenibilità: eseguire un prompt richiede un elevato assorbimento di energia, meglio essere parchi nelle richieste, proprio come se avessimo di fronte un umano che può dedicare tempo e risorse limitate per portare a termine un determinato compito.
Di seguito gli esperimenti che abbiamo trovato più interessanti.
Immagini
Ai lettori più attenti non saranno sfuggiti due immagini commissionate a Midjourney (con DALL-E, l’omologa AI di OpenAI, ci siamo trovati meno bene): una tavola con lo stile di Bruegel per illustrare i moderni lavori a distanza, e una che fosse suggestiva del fenomeno dei repentini cali di temperatura in questa epoca di riscaldamento globale. In entrambi i casi abbiamo dichiarato il promt e accreditato l’AI autrice. Sono due semplici esperimenti secondo noi piuttosto ben riusciti (altri decisamente meno non sono stati ritenuti degni di pubblicazione…).

L’ambito della generazione delle immagini (text to image, ma già ci sono esperimenti di text to video) è uno dei più frequentati e sta generando discussioni già molto accese tra gli artisti produttori di immagini originali. Una delle questioni dibattute è se sia etico e legittimo istruire l’intelligenza artificiale a produrre immagini e disegni nello stile di artisti che, con la propria creatività, hanno prodotto stili originali e riconoscibili. Per questo abbiamo evocato Bruegel: morto nel 1569, non se ne avrà a male (né lui né gli eventuali eredi).
C’è poi la questione dei deep fake: notissimi quelli dell’arresto di Trump e del papa col piumino (che sia stato questo a risvegliare il Garante dal torpore?). Altri, più cerebrali, dibattono se le AI generino davvero nuovi contenuti o se piuttosto ci stiano inondando di più banali, per quanto suggestivi, déjà vu. Mentre sperimentiamo, seguiamo l’evolvere delle discussioni. In ogni caso per ora le AI che generano immagini non sono state ammonite dal garante.
Estrazione dati
L’AI può fare velocemente del lavoro sporco, che in genere nessuno vuole fare. In una redazione un lavoro tipico è leggere un testo e ricavarne, meccanicamente ma con un certo dispendio di tempo e intelletto, alcuni dati utili. Abbiamo utilizzato ChatGPT per ottenere velocemente un elenco di ricercatori citati da una inchiesta pubblicata da L’Espresso sui professori universitari emergenti. Dopo aver copiato e incollato il testo nella chat abbiamo chiesto in linguaggio naturale: «Fai una tabella con nome, dipartimento, università». Questo il risultato ottenuto in circa due secondi:
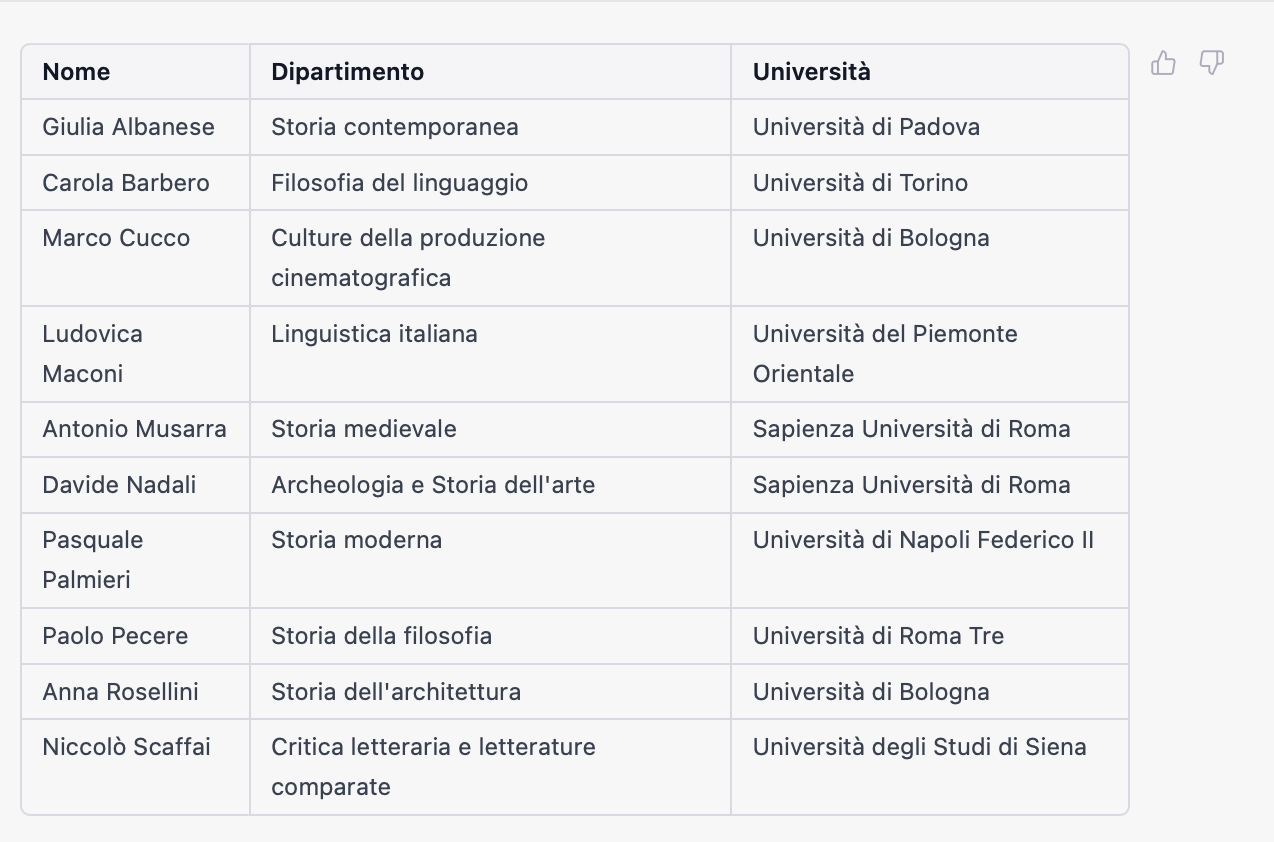
Lavoro ben eseguito, niente da aggiungere. In questo caso è anche difficile dimostrare che un umano fosse in attesa di poter eseguire il compito: di solito scappano tutti quando lo si propone in redazione.
Mappe interattive
Si sa che con il codice ChatGPT ci sa fare. In rete si trovano esempi molto più elaborati del nostro ma noi abbiamo potuto verificare che una persona non esperta in codice ottiene del codice funzionante perché l’AI è in grado di interpretare correttamente l’intenzione espressa anche tramite una richiesta piuttosto generica. Vediamo.
Abbiamo chiesto: «scrivi il codice di un grafico interattivo con i dati covid italiani che trovi su Github». ChatGPT ha risposto descrivendo i passaggi per ottenere la mappa collegandosi ai dati pubblicati dalla Protezione civile su Github.

Avrete notato che non abbiamo specificato quali dati usare, ma ChatGPT ha costruito il grafico con i “nuovi casi giornalieri”, che probabilmente è il dato che anche un umano avrebbe scelto. Da notare che il file della Protezione civile non contiene la stringa “nuovi casi giornalieri”. Troviamo invece questa struttura:
“data”:”2020-02-24T18:00:00″,
“stato”:”ITA”,
“ricoverati_con_sintomi”:101,
“terapia_intensiva”:26,
“totale_ospedalizzati”:127,
“isolamento_domiciliare”:94,
“totale_positivi”:221,
“variazione_totale_positivi”:0,
“nuovi_positivi”:221,
“dimessi_guariti”:1,
“deceduti”:7,
“casi_da_sospetto_diagnostico”:null,
“casi_da_screening”:null,
“totale_casi”:229,
“tamponi”:4324,
“casi_testati”:null,
“note”:null,
“ingressi_terapia_intensiva”:null,
“note_test”:null,
“note_casi”:null,
“totale_positivi_test_molecolare”:null,
“totale_positivi_test_antigenico_rapido”:null,
“tamponi_test_molecolare”:null,
“tamponi_test_antigenico_rapido”:null
ChatGPT ha compiuto una scelta (o per lo meno questa è l’impressione, ma sappiamo che il modello di ChatGPT giustappone le parole in base alla frequenza con cui compaiono nei testi usati per l’addestramento): ci ha dato i “nuovi casi giornalieri” a cui ha ricondotto i dati descritti dalla stringa “nuovi_positivi” presente nel file della Protezione civile.
Il grafico ottenuto è funzionante e usabile, uno sviluppatore ha ora una buona base su cui lavorare per affinare il risultato.
Domande e risposte su specifici documenti
ChatGPT risponde alle nostre domande utilizzando le informazioni che si trovano nell’enorme dataset di addestramento. Però può essere utile sviluppare un servizio di risposte basate su uno specifico dataset di informazioni più controllate: per esempio gli articoli pubblicati da Scienza in rete. Di seguito l’esperimento condotto tramite Google Colab (nel primo link trovate spiegato nel dettaglio come costruire il proprio personale chatbot).
Posizionandosi nelle ultime righe del file qui sotto potete vedere che abbiamo posto a ChatGPT una domanda dopo che abbiamo indicato un documento preciso come fonte della risposta, un recente articolo sulle materie prime critiche. La risposta non è molto centrata, manca probabilmente un addestramento specifico sul documento ma rende comunque bene l’idea di come potrebbe essere in futuro la funzione del “cerca nel sito”: non più un elenco di link ma una risposta precisa a partire dai contenuti pubblicati.

Testi
Venerdì, quando ormai la newsletter settimanale era completa e pronta da spedire, abbiamo letto la comunicazione del Garante. Abbiamo pensato che avesse senso far scrivere il testo proprio a ChatGPT a partire da un articolo di Politico.org (da notare che raramente l’Italia finisce su riviste internazionali per questioni tecnologiche…). È l’utilizzo più classico, la scrittura dei contenuti, notoriamente una delle mansioni intellettualmente più faticose per l’essere umano. In questo caso abbiamo fatto quello che si fa quando arriva in redazione un testo scritto da una persona in carne e ossa: si verifica la notizia e si pubblica indicando autore e fonte.
L’autorità italiana per la protezione dei dati personali ha ordinato il blocco temporaneo dell’uso di ChatGPT, il popolare strumento di intelligenza artificiale creato da OpenAI, a causa di presunte violazioni della legge sulla protezione dei dati dell’UE. L’autorità ha dichiarato che OpenAI non ha fornito una base legale sufficiente per la raccolta e la conservazione dei dati personali degli utenti per “addestrare” gli algoritmi di ChatGPT, e ha inoltre affermato che l’azienda non verifica l’età degli utenti, esponendo i minori a risposte inadatte rispetto al loro grado di sviluppo e consapevolezza. OpenAI ha 20 giorni per comunicare come intende mettere ChatGPT in conformità con le regole sulla privacy dell’UE, altrimenti rischia una sanzione fino al 4% del suo fatturato globale. La società non ha ancora rilasciato una dichiarazione in merito.
Dare le giuste mansioni alla AI
Abbiamo anche riso delle famose allucinazioni in cui l’abbiamo malignamente indotta: la tentazione era troppo forte. Ma, come dimostrano i nostri primi ingenui tentativi, imparando a fare le domande giuste, quelle a cui può rispondere, abbiamo capito che la collega AI è qui per rimanere con noi con nostra grande soddisfazione. Vale la pena quindi di ragionare a fondo su questa potente tecnologia, capirne i fondamenti teorico scientifici e sottoporla a un dibattito pubblico il più partecipato possibile evitando invece di depotenziarla tramite una fragile impalcatura di divieti.
fonte: https://www.scienzainrete.it/articolo/ci-mancherai-collega-ai/sergio-cima/2023-04-03
l’Autore Sergio Cima

Laureato in filosofia, si occupa di data journalism e comunicazione in ambito medico e scientifico. Web editor di Scienza in rete, segue in particolare i new media.




